The document is named the most valuable asset of the business, the enrichment and data optimization to increase the extraction efficiency becomes a key element. Data augmentation be used as a powerful technique to help improve the quality and quantity of data without the need to collect more. This is not only a solution for the problem as shortage of data, but also opened up many opportunities for businesses in the application of artificial intelligence (AI) and machine learning (ML).
Vietnam will help the business understand Data augmentation what is, how it works, the most common techniques and the field application efficiency.
1. Data augmentation is what?
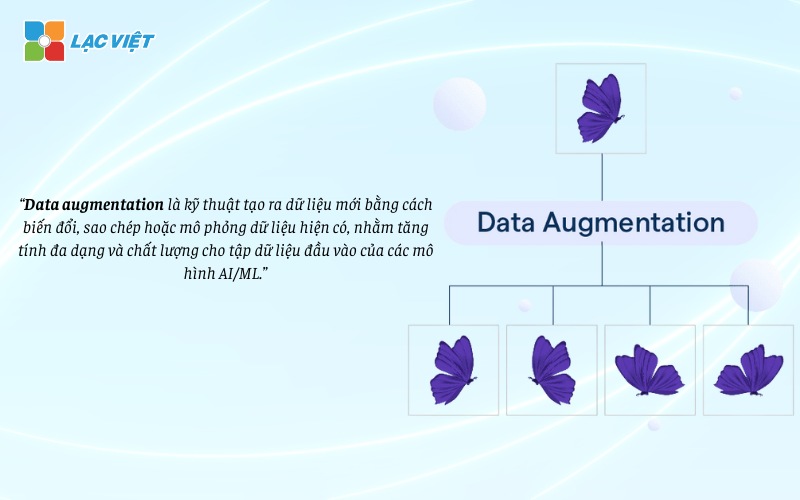
Data augmentation is the technique to create new data by modification, copy, or simulate existing data, in order to increase the diversity and quality for the input data of the model AI/ML.
To the model ML works efficiently, we need the big data variety to training. However, collecting real data with high diversity and large enough scale is often difficult due to limitations of the source data, legal regulations or technical factors.
Through the small changes on the original data, technique of enhancing data not only extend the data set, but also ensure the quality of the input. Currently, the solution artificial intelligence (AI) to create birthday is being used to enhance data quickly, accurately, become useful tools in many industries, from finance, manufacturing to health care, document management.
2. The manner of operation of Data augmentation
Data augmentation is not only the increasing number of data but also the process of organizing, optimizing data in order to serve the specific purpose, such as training machine learning models (ML) or data management business.
Process operation enhanced data usually consists of 3 main steps:
Explore the data
Strengthen existing data
Integrate the data form
2.1 Explore the data set
This is the first step and important to ensure that data input is understood, comprehensive assessment before performing any operation. The aim is to understand the context and limits of current data to build strategies to enhance fit, from which ensure that the input data meets the standards of the system of document management professional.
Analysis of existing data:
- Quality assessment: Search data, faulty, missing or non-uniform.
- Determine the diversity and coverage: Check that the data are sufficiently representative for the case of no need.
Looking for flaws in the data set:
- Detection bias: Consider whether data have focused too much on a group of characteristics which don't, such as focusing only on one type of material or certain language.
- Additional variables can be flawed: For example, for business document management, the variations can be the format contracts, invoices from many different areas.

2.2 strengthen existing data
Data augmentation is the variable factors in the current data to create the data template new with diverse content but retains the validity and value information.
Perform the operation transformation:
- Image: Rotate, flip, crop, change the lighting, or add noise to create the document version of cultural diversity, help system identification more accurate picture.
- Text: Replace synonyms, vary sentence structure, or broaden the context for the system to understand, the handle is many document format, more from meeting to commercial contracts.
- Audio (if applicable): Change the frequency, the more background noise, or adjust the playback speed to improve the ability to handle voice recognition in the document recording.

These tasks help to increase the diversity of data, create conditions for the machine learning models or systems, document management adapted to more realistic scenarios. This is especially useful in the digitization business when have to handle large volumes of documents with the format and content is not homogeneous.
2.3 Integration of form data
After strengthening, the model new data need to be standardized and integrated to serve the specific goals, such as building the repository, smartphone or coaching model WHO.
- Combine data from multiple sources: Merge data from different formats such as image, text, audio to create a system data general and flexible.
- Standardized data: Ensure all data adhere to a common format, help system, document management easy sorting and handling.
- In app document management: The form documents, such as contracts, invoices, or documents in legal...can all be enhanced and integrated to optimize the efficient storage and lookup in the system as LV SureDMS of Vietnam. This creates a synchronized platform, ease of access, ensure high accuracy when tapping material.
3. 5 Types of technical Data augmentation the most popular
3.1 Computer vision
Data augmentation is a technical center in the task computer vision. It helps to create the performance data diversity and solve the imbalance class in the training data. The first application of increasing population in computer vision is through the strengthening of the positions. Specific:
- Image transformations: Use techniques such as rotate, flip, resize or crop the image to create the variations.
- Color adjustment: Change the brightness, contrast or saturation to improve the ability to identify, diversification of input data.
- Add noise: Create photo templates noise to help pattern recognition better in real environment.

In business, this technique helps to digitize documents such as invoices, contracts and receipts with the ability to handle variations on the definition, the shooting angle or light.
3.2 augmented audio data
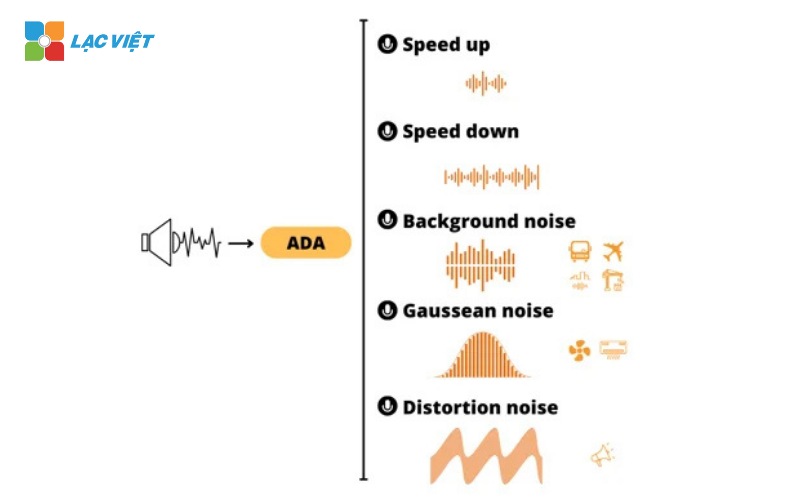
The audio files, such as voice recordings, is also a popular sector that businesses can use augmented data. Data augmentation is often applied to the audio files such as voice recording, notifications or data from the sound sensor.
- Change the speed and pitch: Adjust to create variations sound, help handle pattern diversity of tone and pronunciation.
- Add noise: Create recordings with background noise or sound environment to increase the ability to handle data in real conditions.
- Insert the paragraph breaks: Forward or cut the audio clips to coaching model handle data heterogeneity.
In business, the virtual assistant or customer care, use this technique to get comprehensive, accurate feedback in many different situations.
3.3 enhanced text data
These are important techniques in handling natural language (NLP), application for text documents such as contracts, emails or content from the chatbot. Cevil convert text data include:
- Replaced synonym: Create the variant text with different words, but still hold meaning.
- Shuffled order: Change your location from, or sentences to train models to understand context diversity.
- Delete or insert from: Remove from unnecessary or add additional words to create the template text difference.

In the management system documentation, this technique helps to handle and extract information from a variety of document formats, such as emails or reports.
3.4 Create aggregate data
Create aggregate data based on the characteristics of the original data, usually through advanced algorithms such as Generative Adversarial Networks (GAN). Data augmentation to use the algorithm to create new data has a structure similar to the original data, for example, a picture emulator or content simulation.
Businesses can use the aggregate data to test the process or training the model WHO does not need to collect real data, which saves time and cost.
3.5 Training opposite
This method focuses on the examination and enhance the ability to resist bugs or attack of the pattern AI. From there create the variant data with very small changes, such as interference is not significant on the image or text, to simulate the situation difficult.
In enterprise security, training for paradox helps to check the system's ability to handle the attack or data error.
4. Why business need technical application enhanced data
In today's environment, businesses increasingly dependent on the machine learning models (Machine Learning – ML) and deep learning (Deep Learning – DL) to improve the ability to analyze, make decisions. However, the construction and training of models ML/AI requires a large volume of data quality.
Data Augmentation is an important technique to help improve the quality and efficiency of these models without the need to collect more too much new data. And find out why the technique of enhancing data important to business.
4.1 enhance the performance model, ML and DL
Machine Learning models and Deep Learning requires a wide variety of data to learn, giving accurate predictions. Strengthening data help to enrich the original data, create many different variations from the original data. Then, the model will be trained with the feature more diverse, from which enhance the ability to generalize, improve performance in real-world environments.
Specifically, businesses can use techniques such as rotate, change the brightness or change the color of materials to create variations of the input data. This helps the model learn from different situations, not just stop in the training data initially. Thanks to such model can predict more accurate, more flexible, responsive with many real-life situations, different in the process of operating the business.
4.2 Reduce dependence on data
One of the big problems in the training of the model ML is the collection and preparation of large amounts of data. This is not only expensive in terms of cost but also loss of time. Data Augmentation helps businesses minimize the collection of new data by taking advantage of the maximum available data.
Businesses can use these techniques to strengthen as creating aggregate data or change the data attributes (such as light, angle of rotation of the image) to complement the data set is available. This not only saves costs but also helps the model is learned from a source of richer data without scaling collect.
4.3 minimize Overfitting
Overfitting is a phenomenon when a machine learning models only well versed in the predictions on the training data, but have difficulty in applying knowledge to new data. This condition usually occurs when the training data is too narrow and does not represent the complete possible situations encountered in practice. The strengthening of data to help create rich variations, preventing the pattern too joints in the training data.

The business will feel the effects markedly when the model not only works well on training data but also can make accurate predictions in real-world situations. Data augmentation helps the model learn from many different data types, minimize the possibility of exceeding the joints and helps the system identification documents, text or images, is more accurate when applied to real work.
4.4 Improved data privacy
When using sensitive data such as customer information, financial data or legal document, the protection of the privacy of data becomes extremely important. The technique of enhancing data helps to create aggregate data which does not reveal sensitive information. This is especially useful in the industry require high security, such as financial or health.
Businesses can use aggregate data instead of using the original data to train the models deep learning. This not only helps to protect privacy but also minimize the risks violation of data security. Pattern can still learn the important characteristics that are not directly in contact with sensitive data.
5. Data augmentation is applied in any field?
Data Augmentation has been widely used in many industries, help to improve the performance of the machine learning models (ML) and deep learning (DL). This app not only optimizes results but also help enterprises minimize costs, time collecting data. Here are a number of areas which techniques to strengthen data to be applied:
5.1 Financial – accounting
In the financial sector, strengthening data can create the fraud case simulator to train the model to detect fraud, thereby helping the system analysis and identification of unusual transactions, from which minimize risk for the business.

Creating transactions emulator helps machine learning models identify patterns unusual transactions in the bank, credit card, or online transactions. In addition, this technique also supports improved prediction of credit risk, help banks identify customers, potential risks.
5.2 Production
In the manufacturing industry, the use of Data augmentation helps to improve the machine learning models in detecting defective products. The model can be trained with the variant image of the product to identify defects or errors in the manufacturing process.

The production company may use image intensification to detect the error as small as scratches, cracks on the surface of the product, this helps minimize the number of defective products put on the production line and increase productivity.
5.3 retail
Enhanced data plays an important role in the retail industry, where the machine learning models used for classification, product optimization, demand forecasting and personalize the customer experience.
Enhanced image data of the product can help the model get comprehensive product range in various conditions such as low light, shooting angle, different or complex background. This helps improve the ability to identify products, create shopping experience smoother for the customer.
5.4 document Management
Data augmentation also has important applications in the management of material, especially in the process of digitizing documents from the print or scan. Technologies such as OCR combined with techniques to strengthen data can help identify, handle the complex document, from which optimized the process of storing and searching for information.

Lac Viet apply techniques to strengthen data to the systems management documentation such as LV SureDMS. The use of OCR in conjunction with enhanced data help improve the ability to recognize documents with complex formatting or the text in the language less popular. This helps to improve accuracy when sorting, searching, document storage.
5.5 health –
In the medical industry, particularly diagnostic imaging, the strengthening of data to help improve the ability to detect and identify diseases from medical images such as X-ray, CT scan or MRI. Through the creation of variants of pictures (for example, rotate, zoom, change the brightness), the machine learning models can identify diseases such as cancer, tumors or lesions without encountering limitations of data deficiency.
The creation of the medical image synthesis enhances data for these rare diseases, where the number of original images very little. This not only improves the diagnostic capabilities but also help protect the privacy of patients when using the aggregate data instead of actual data.
Data augmentation not only is a technical support in the process of developing AI/ML, which is also strategic solutions to help businesses optimize data and improve operational efficiency. With the ability to create high-quality data, widely used in many industry, this technique brings great opportunity for businesses to break in the digital age.
CONTACT INFORMATION:
- Lac Viet Computing Corporation
- Hotline: 0901 555 063 | (+84.28) 3842 3333
- Email: info@lacviet.vn – Website: https://lacviet.vn
- Headquarters: 23 Nguyen Thi Huynh, P. 8, Q. Phu Nhuan, Ho Chi Minh city